#ai
#cheerio

AI 시대에도 직접 글을 읽고 요약하는 능력을 길러야 한다는 취지로 요약의 정석: 요정 이라는 프로젝트를 진행 중에 있다. 기존엔 원문을 사용자가 직접 작성(혹은 복붙)해야 했는데, 이 수고를 덜기 위해 링크 입력 기능을 추가하여 원문을 크롤링해 가져올 수 있도록 업그레이드 시키기로 했다! 👊
1️⃣ 크롤링 구현
웹 크롤링 기능을 구현하기 위해 cheerio 라이브러리를 사용했다. 전체 흐름은 URL 패칭 → HTML 파싱 → 노이즈 제거 → 본문 영역 탐색 → 텍스트 정제 5단계로 구성된다.
URL 패칭
const response = await axios.get(url, {
timeout: 10000,
headers: {
'User-Agent': 'Mozilla/5.0 (compatible; YojeongBot/1.0)',
Accept: 'text/html,application/xhtml+xml',
'Accept-Language': 'ko-KR,ko;q=0.9,en;q=0.8',
},
maxRedirects: 5,
responseType: 'text',
});axios.get으로 HTML을 가져온다. 한국어 콘텐츠 대상이라 Accept-Language: ko-KR을 설정하고, 10초 타임아웃과 최대 5회 리다이렉트를 허용한다.
HTML 파싱
const html = response.data;
if (!html || typeof html !== 'string') {
return { status: 'fetch_failed', content: null };
}cheerio.load(html)로 서버사이드 DOM을 생성한다. cheerio는 jQuery 스타일 API를 제공하는 경량 HTML 파서로, 브라우저 없이 DOM 조작이 가능하다.
노이즈 제거
/** HTML에서 본문 텍스트를 추출 (CONTENT_SELECTORS 우선 탐색 → 실패 시 body 전체) */
export function extractText($: cheerio.CheerioAPI): string {
$(REMOVE_SELECTORS.join(', ')).remove();
for (const selector of CONTENT_SELECTORS) {
const el = $(selector);
if (el.length > 0) {
const text = el.first().text();
const cleaned = cleanText(text);
if (cleaned.length > 0) {
return cleaned;
}
}
}
return cleanText($('body').text());
}상수 REMOVE_SELECTORS에 정의된 요소들(script, style, nav, header, footer ...)을 DOM에서 먼저 제거한다. 본문과 무관한 UI/광고/댓글 영역을 사전에 걸러내는 단계이다.
본문 영역 탐색
CONTENT_SELECTORS 배열(article → [role="main"] → main → .post-content → .entry-content 등)을 순서대로 탐색한다. 먼저 매칭되면서 텍스트가 1,000자 이상인 셀렉터의 본문을 채택한다. 모든 셀렉터가 실패하면 body 전체 텍스트를 fallback으로 사용한다.
텍스트 정제
/** 연속 공백/개행을 정리하여 깔끔한 텍스트로 변환 */
export function cleanText(raw: string): string {
return raw
.replace(/\n{3,}/g, '\n\n') // 3줄 이상 연속 개행 → 2줄로 축소
.replace(/[^\S\n]+/g, ' ') // 개행 제외 연속 공백 → 단일 공백
.trim();
}3줄 이상 연속 개행을 2줄로, 연속 공백을 단일 공백으로 정규식 치환하여 깔끔한 텍스트를 만든다.
2️⃣ 원문 처리
단순히 링크 입력 + 크롤링 기능만 추가하면 될 것 같았지만 생각해야할 부분이 너무 많았다. 그 중 첫 번째는 가져온 원문이 요약 가능한 글인지에 대한 확인 여부였다. 처음엔 크롤링 기능만 구현하려 했으나 요약이 충분히 가능한 글인지에 대한 검증을 거치지 않으면 사용자가 실수로 다른 링크를 넣었거나, 원치 않는 분석 결과를 얻게 될 경우에 대한 처리가 불가하다고 판단했다.
AI 없이 판단 가능한 것들
- 로그인 필요: HTTP 응답 코드가 401, 403이거나 로그인 페이지로 리다이렉트된 경우
- 페이지 자체를 못 가져옴: 404, 500 등
- 텍스트가 너무 적음: 추출된 텍스트가 N자 미만이면 "내용이 부족하다"고 판단
- JS로만 렌더링되는 SPA: fetch로 받은 HTML에 본문이 거의 없는 경우
AI 없이는 애매한 것들
- 텍스트는 있는데 의미 있는 글이 아닌 경우 (상품 목록, 버튼 텍스트 모음 등)
- 텍스트 양은 충분한데 요약할만한 내러티브가 없는 경우
그렇게 ai를 활용하기로 결정했고, 우선 ai에게 내가 긴 글이 포함되지 않은 링크를 주며 요약을 부탁하면 너는 어떻게 판단해? 라고 물어봤다. 니가 해야될 일이니까....
글이 없는 링크의 경우
예를 들어 쇼핑몰 상품 페이지라면 요약이라는 개념 자체가 맞지 않으니 대신 가져온 내용 기반으로 상품명, 가격, 주요 스펙, 특징 같은 걸 정리하는 방식으로 자연스럽게 전환된다.
페이지를 아예 못 읽는 경우
로그인이 필요한 페이지이거나, JavaScript로만 렌더링되는 SPA라서 콘텐츠가 없거나, 접근 자체가 막힌 경우엔 페이지의 내용을 가져올 수 없다고 전달하고 가능하면 대안을 제안한다.
읽을 수 있지만 내용이 빈약한 경우
가져온 HTML에 텍스트가 거의 없거나 메타 정보만 있는 경우엔 그 정보 내에서 최대한 파악한 걸 알려주지만, 충분한 정보가 없어 한계가 있다고 함께 전달한다.
링크를 받으면 무조건 요약이 아닌 가져온 내용의 성격에 맞게 응답 방식을 조정하는 것이라고 한다.
원문 글자 수 검증
기존의 원문을 직접 작성하던 방식에선 원문의 길이를 1000자 이상, 5000자 이하로 제한해두었기 때문에 크롤링해 가져온 원문에도 동일한 제한을 두기로 했다. 원문을 추출한 뒤 글자 수가 5000자가 넘으면 slice 함수로 원문을 잘랐고, 1000자 미만이면 요약 불가로 처리하기로 결정했다.
3️⃣ API 명세
위 1번에서의 경우들을 전부 따졌을 때 총 5가지의 경우로 나뉜다고 판단했고, 사용자에게 추출된 원문에 대한 상태를 텍스트로 제시하기 위해 위의 각 상태를 api 응답에 추가하기로 했다.
Response: 200 OK
{
success: true,
data: {
status: "success" | "truncated" | "under_limit" | "unsuitable_content" | "fetch_failed",
content: string | null // fetch_failed, under_limit일 경우 null
}
}- success : 1000 ~ 5000자 범위로 원문이 정상 추출됨
- truncated : 원문이 정상적으로 추출되었으나 5000자 초과로 잘림
- under_limit : 1000자 미만으로 요약 불가
- unsuitable_content : 텍스트는 있으나 요약하기 어려운 내용
- fetch_failed : 페이지 접근 불가 (로그인 필요, 404 등)
// src/constants/message.ts
export const MESSAGE = {
EXTRACT: {
SUCCESS: '원문을 불러왔어요!',
TRUNCATED: '원문을 불러왔어요! 원문이 길어 앞 5000자만 분석에 사용돼요.',
UNSUITABLE: '요약하기 적합하지 않은 글이에요. 요약 결과가 다소 부정확할 수 있어요.',
UNDER_LIMIT: '원문이 너무 짧아 분석이 어려워요. (1000자 이상의 글을 입력해주세요.)',
FAILED: '페이지를 불러올 수 없어요. 링크를 다시 확인해주세요.',
},
};
// src/hooks/extract/useExtractStatus.ts
interface ExtractStatusResult {
isUsable: boolean;
message: string;
}
const STATUS_MAP: Record<ExtractStatus, ExtractStatusResult> = {
success: { isUsable: true, message: MESSAGE.EXTRACT.SUCCESS },
truncated: { isUsable: true, message: MESSAGE.EXTRACT.TRUNCATED },
unsuitable_content: { isUsable: true, message: MESSAGE.EXTRACT.UNSUITABLE },
under_limit: { isUsable: false, message: MESSAGE.EXTRACT.UNDER_LIMIT },
fetch_failed: { isUsable: false, message: MESSAGE.EXTRACT.FAILED },
};
export const useExtractStatus = (status: ExtractStatus | null): ExtractStatusResult | null => {
if (!status) return null;
return STATUS_MAP[status];
};각 상태에 따른 메세지를 상수로 분리했고, api 응답의 상태 값을 인자로 받아 원문 요약 가능 여부와 메세지를 한 번에 리턴받을 수 있도록 useExtractStatus 훅을 작성했다.
이후 페이지 전환에 사용하기 위해 원문이 1000자 미만인 under_limit, 원문 추출에 실패한 fetch_failed는 isUsable 값을 false로 처리했다.
4️⃣ 요약 가능 판단 프롬프트
ai에게 텍스트 품질 검증 전문가라는 직업을 심어주었고... 요약이 가능할 만한 글인지에 대한 여부와 그에 대한 간단한 이유를 JSON 형식으로 반환하도록 작성했다.
## 판단 기준
위 텍스트가 **요약할 만한 의미 있는 본문**인지 판단하세요.
**isSuitable: true 인 경우:**
- 기사, 블로그 글, 에세이, 논설문 등 논리적 구조가 있는 글
- 특정 주제에 대해 설명하거나 주장하는 글
- 읽고 요약할 수 있는 충분한 내용이 있는 글
**isSuitable: false 인 경우:**
- 네비게이션 메뉴, 버튼 텍스트, 링크 목록 등 UI 요소의 나열
- 로그인 폼, 에러 페이지, 검색 결과 목록 등 구조적 페이지
- 상품 스펙, 가격표 등 단순 데이터 나열
- 의미 없는 텍스트 조각이나 깨진 인코딩
- 여러 글의 제목/미리보기만 나열된 목록형 페이지
---
## 출력 형식 (JSON만 반환)
{
"isSuitable": true 또는 false,
"reason": "판단 이유를 한 문장으로 간단히 설명"
}추출된 원문이 1000자 이상일 때 위의 프롬프트를 통해 요약 적합성을 판단한 후, isSuitable이 false이면 unsuitable_content를 반환, true이면 5000자 이하인지 검증하는 구조이다.
5️⃣ UX 개선
원문 처리 다음으로 고민한 부분...
기존 페이지는 원문 작성 페이지와 요약 작성 페이지가 분리되어 있었고, 요약 작성 페이지에서 로컬 스토리지를 통해 이전 페이지의 원문 값을 가져와 요약 분석 요청 api에 함께 보내는 구조였다.
원문과 로컬 스토리지 값 동기화
원문 작성만 존재할 땐 사용자가 입력한 값을 그대로 저장하면 됐기 때문에 문제가 없었지만, 링크 입력 방식이 추가되면서 각 모드에 맞게 로컬 스토리지와 원문 값을 일치시켜야 하는 문제가 생겼다.
- 원문 작성 모드 : 사용자가 textarea에 직접 입력한 값이 state로 관리되는
userContent(원문)에 들어감. - 링크 입력 모드 : 크롤링 API 응답으로 추출된 원문이
setUserContent(res.data.content)로 들어감. 하지만 링크 모드일 때는 textarea가 렌더링되지 않기 때문에 화면에 보이지 않고 내부적으로만 보관됨.
원문 데이터는 다음 단계 버튼을 눌러야 로컬 스토리지에 저장되는데, 링크 모드로 원문 추출 -> 다음 페이지로 이동한 뒤 다시 원문 작성 페이지로 돌아옴 -> 원문 작성 모드로 전환 과 같은 흐름이 이어진다면 원문 작성 textarea에 링크 모드로 추출된 원문 값이 남아있는 문제가 생긴다.
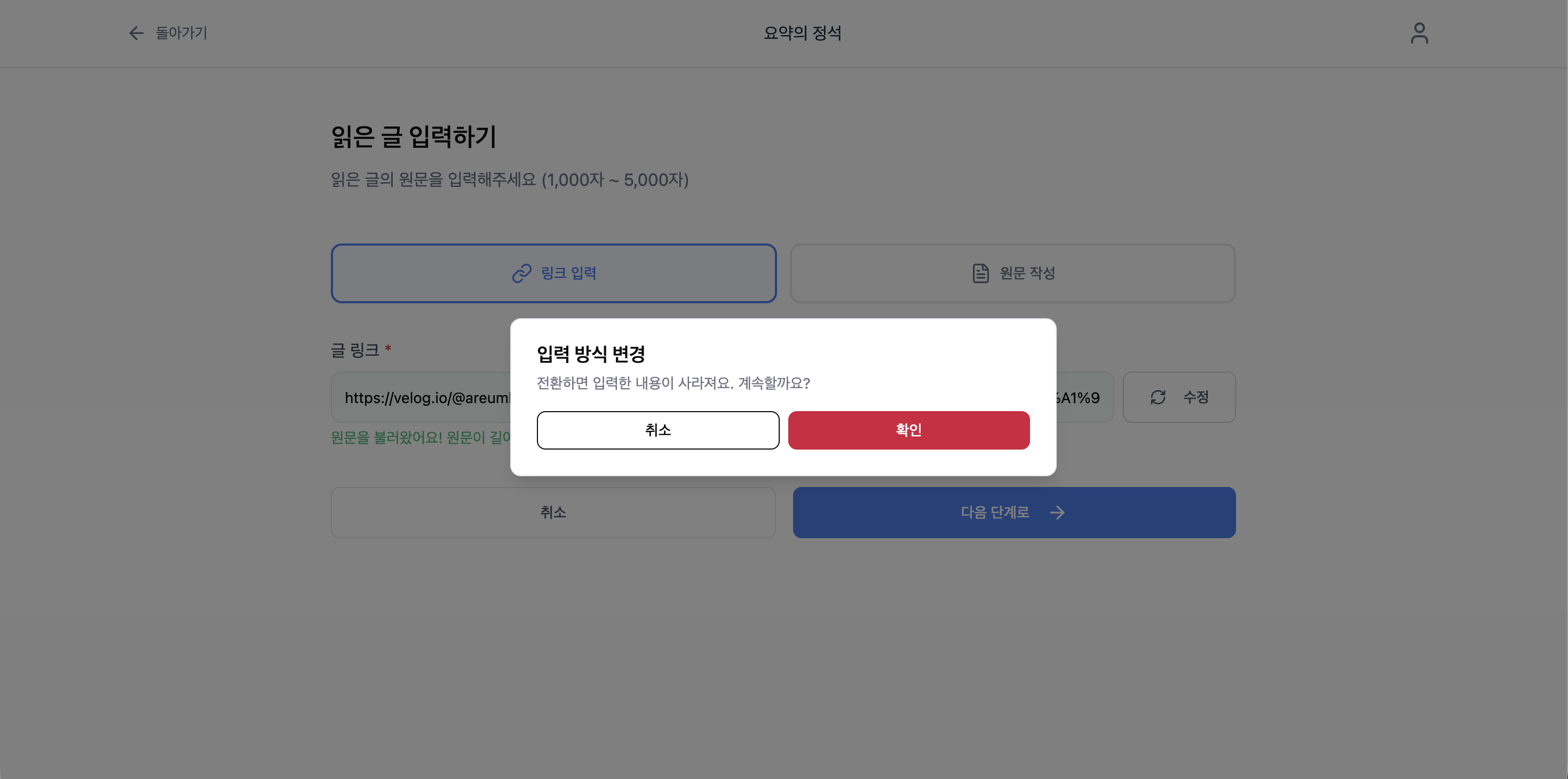
위 문제 해결을 위해 모드 전환 시 사용자에게 모달을 제시하도록 했다. 확인 버튼을 누르면 url, 원문, 추출 상태, 로컬 스토리지 값을 모두 비운다.
// 전체 데이터 흐름
[원문 입력 페이지]
│
├─ 링크 모드: URL 입력 → 크롤링 API → userContent에 추출 원문 저장 (화면에는 미표시)
├─ 텍스트 모드: textarea 입력 → userContent에 직접 저장
│
├─ 모드 전환 (입력값 있을 때) → 모달 확인 → state + localStorage 초기화
│
├─ "다음 단계로" 클릭 → localStorage에 저장 → /summary 이동
│
└─ 뒤로 가기로 재진입 → useEffect에서 localStorage 복원
[요약 입력 페이지]
│
├─ useEffect에서 localStorage 읽기 → 원문 없으면 /input으로 리다이렉트
│
└─ "AI 분석 시작" 클릭 → API 호출 → localStorage 삭제 → 메인으로 이동
원문 추출 후 링크 수정 방지
만약 원문 추출이 완료된 이후 링크 값을 수정한다면 링크와 추출된 원문 값 사이에 불일치 문제가 생기게 된다. 해당 문제가 일어나지 않도록 원문 추출 여부 상태 값 isContentLoaded을 선언했고, 이를 링크 input 컴포넌트의 readonly 속성에 사용했다.
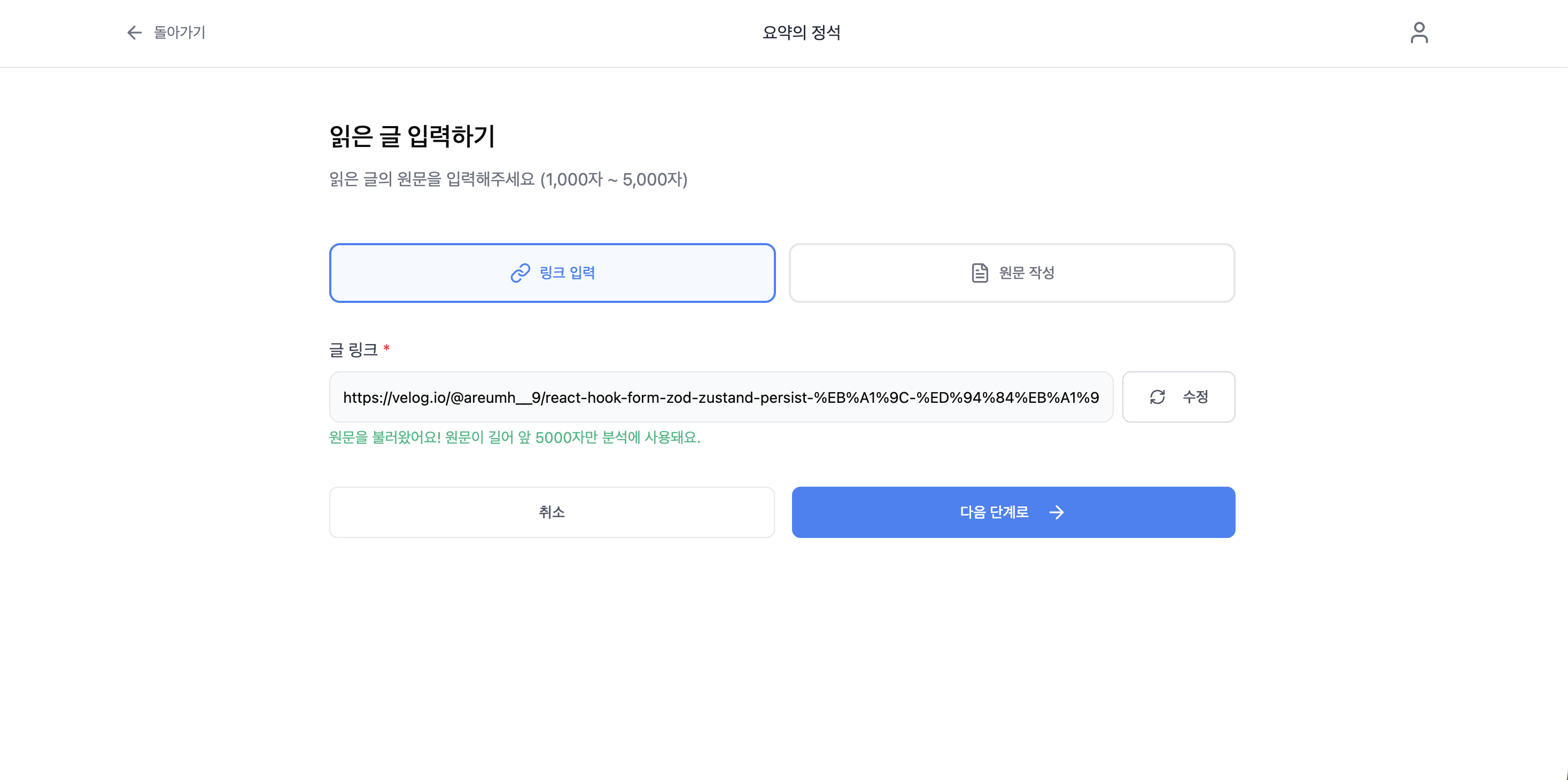
<Input
id="url"
type="url"
placeholder="https://example.com/article"
value={url}
onChange={(e) => setUrl(e.target.value)}
readOnly={isContentLoaded}
className={`... ${isContentLoaded ? 'bg-app-gray-50 cursor-not-allowed' : ''}`}
/>추출이 완료되면 Input은 읽기 전용으로 잠기고, 배경 색이 바뀌어 시각적으로도 수정 불가 상태가 된다. 원문 추출 버튼도 isContentLoaded 값에 따라 전환된다.
{isContentLoaded ? (
<Button onClick={resetInputText}>
<RefreshCw className="w-4 h-4 mr-2" />
수정
</Button>
) : (
<Button
onClick={handleExtract}
disabled={!isValidUrl(url) || isExtracting}
>
{isExtracting ? '불러오는 중...' : '원문 불러오기'}
</Button>
)}- 추출 전 : 원문 불러오기 버튼이 표시됨.
isValidUrl(url)로 URL 형식이 유효한지 검증하고, 유효하지 않으면 버튼 비활성화 - 추출 후 : 수정 버튼으로 전환됨. 클릭하면
resetInputText()가 호출되어 URL, 원문, 추출 상태가 모두 초기화되고 처음부터 다시 입력 가능
URL을 부분 수정하는 것은 허용하지 않고, 초기화 후 새로 입력하는 방식으로 링크와 원문 간의 불일치 문제를 원천 차단했다. 👍